Recently, Benjamin McKenna and I put out a paper on the arxiv about the injective norm of random real and complex tensors, and the geometric entanglement of random uniform quantum states (which as the name might not suggest, is directly related to the injective norm1).
The injective norm is a natural generalization of the operator norm of a matrix. Actually it is really a family of norms as for the operator norms and, in our paper, we are only interested in one instance. Namely, given 

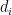


where 
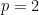

Exemplifying this notion with tensors coming from well known quantum states, we have:
- Bell state:
, that is the tensor (here matrix) has components
. Obviously, its injective norm is
.
- W state: In this case,
and
, one has
so that the corresponding tensor has non vanishing components
and we compute
.
In general, computing the injective norm of a tensor is a difficult problem, in fact, trying to optimize the defining function is NP-hard. This is one of the motivation behind our work. Computing the injective norm of tensors and quantum states is hard, but it has many applications. Indeed, this injective norm is one of the few measures of genuine multipartite entanglement, and as such plays an important role where such measures are useful, namely quantum computing, quantum information theory, phase transitions in topological materials… It also appears naturally in the field of statistical physics: The injective norm is directly related to the ground-state energy of some (spherical) spin glasses. Finally, it’s also studied in data analysis and statistics, for the hidden clique problem or when considering the problem of tensor PCA and independent component analysis.
The main theorem of our paper informally states that with high probability as 

where 




On top of that, we also study the situation 


where 


To prove this theorem we reprove a slightly degenerate version of the Kac-Rice formula, and use the average count of critical point thus obtained to bound the excursion probability of a process of the form 




As Kac-Rice practitioners are well aware of, the main bottleneck when working with the formula is whether or not the resulting random matrix one has to understand is manageable or not. A lot of the studied cases in the literature are limited to relatively simple random matrices (typically simple modification of GOE random matrices). In our case, we are far from the GOE or relatively integrable random matrices, and so we strongly rely on recent techniques developed by Benjamin McKenna as well as Gérard Ben Arous and Paul Bourgade to understand the asymptotics of our random matrix integrals. However, we have to extend the domain of validity of those techniques, as some of the assumptions they rely on are not satisfied by our random matrices, therefore making them more robust. Furthermore, we also need recent random matrix inequalities that were recently obtained by Afonso S. Bandeira, March T. Boedihardjo, Ramon van Handel and resulting from the interpolation between free probablistic and classical random variables.
Well, now you know that it’s full of beautiful and interesting maths, so if you want to know more, you can read the paper!
- It’s also directly related to another measure of entanglement named « Groverian » because of the role it plays in estimating the success probability of (possibly variations of) Grover’s algorithm. All those measures are basically the same, up to choices of conventions.
Note that the injective norm is also often known as the spectral norm of a tensor, or sometimes simply called largest singular value (or, in my opinion, a bit badly but it’s rare, eigenvalue) of a tensor. ↩︎
