In a coming paper I will use Kac-Rice formula to study a question motivated by quantum information. So I decided it’d be a nice time to try to give a short account on the well known formula.
First a disclaimer, I am certainly not an expert on the specifics of the formula or the random geometry aspects that are tied to it. However, I’ve learnt a good amount of beautiful and enjoyable mathematics while working with it, so that I’d like to share a few very simple remarks about it.
What is Kac-Rice formula?
Let’s say 



![\mathbb{E}(N_u(\phi))=\int_{\mathbb{R}^{n}}\text{d}x\mathbb{E}[\lvert\det\partial_{x_i}\phi^j(x)\rvert:\phi(t)=u] \rho_{\nabla \phi(t)}(0).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%28N_u%28%5Cphi%29%29%3D%5Cint_%7B%5Cmathbb%7BR%7D%5E%7Bn%7D%7D%5Ctext%7Bd%7Dx%5Cmathbb%7BE%7D%5B%5Clvert%5Cdet%5Cpartial_%7Bx_i%7D%5Cphi%5Ej%28x%29%5Crvert%3A%5Cphi%28t%29%3Du%5D+%5Crho_%7B%5Cnabla+%5Cphi%28t%29%7D%280%29.&bg=ffffff&fg=000&s=0&c=20201002)




In fact, it is much more general (see the Book of Adler and Taylor « Random fields and geometry » for technical aspects and a wonderful amount of beautiful geometry and probability). Let 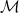










![\mathbb{E}\left(N_u(f,h,B)\right)=\int \text{d}\text{Vol}_g(t) \mathbb{E}[\lvert\text{Jac}_{\phi(t)} \rvert \mathbf{1}_{h(t)\in B}:f(t)=u]\rho_{\nabla f(t)}(0).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%28N_u%28f%2Ch%2CB%29%5Cright%29%3D%5Cint+%5Ctext%7Bd%7D%5Ctext%7BVol%7D_g%28t%29+%5Cmathbb%7BE%7D%5B%5Clvert%5Ctext%7BJac%7D_%7B%5Cphi%28t%29%7D+%5Crvert+%5Cmathbf%7B1%7D_%7Bh%28t%29%5Cin+B%7D%3Af%28t%29%3Du%5D%5Crho_%7B%5Cnabla+f%28t%29%7D%280%29.&bg=ffffff&fg=000&s=0&c=20201002)
What is it used for?
Of course this questions has many answers. Certainly, a bit of generalities can’t hurt. The story started in the 40’s, with the work of M. Kac and S.O. Rice. Kac worked out the formula to study the number of real roots of a random polynomial and published his work in 1943. On the other hand Rice was interested in the « singing of transmission lines ».
A big part of nowadays use of Kac-Rice formula is to estimate the number of critical points of a random function, with the underlying idea that random functions are good representatives of complicated functions. For instance, the hamiltonian of a glassy system, being a disordered system, will typically be complicated to describe and have a lot of metastable states. Similarly the cost function used in machine learning (ML), will be complicated and have many local maxima, minima and low/high index critical points. Understanding the number of critical points at different value of the energy (for glassy systems) or of the cost (ML) can tell us whether their is a chance at optimizing the function in a reasonable amount of time (where optimizing will mean reaching equilibrium in the context of physical systems and finding the « best » model in ML).
Easy examples
Let’s have a look at how to use the Kac-Rice formula on simple examples. Some of those examples were discussed with Guillaume Dubach and Camille Male during an informal and improvised presentation of Kac-Rice formula.1
Law of critical points of random degree 2 polynomials: Consider the following simple but still illustrative example. Set 








According to Kac-Rice formula we have ![\mathbb{E}\left(N_0(P',P,B)\right)=\int_{I\subseteq\mathbb{R}}\text{d}x \mathbb{E}[\lvert a\rvert\mathbf{1}_{P(x)\in B}:2ax+b=0]\rho_{P'(x)}(0).](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%28N_0%28P%27%2CP%2CB%29%5Cright%29%3D%5Cint_%7BI%5Csubseteq%5Cmathbb%7BR%7D%7D%5Ctext%7Bd%7Dx+%5Cmathbb%7BE%7D%5B%5Clvert+a%5Crvert%5Cmathbf%7B1%7D_%7BP%28x%29%5Cin+B%7D%3A2ax%2Bb%3D0%5D%5Crho_%7BP%27%28x%29%7D%280%29.&bg=ffffff&fg=000&s=0&c=20201002)


We also need the law of 
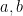

and from there just computing the usual conditional covariance formula for
Indeed, this is sufficient to determine the conditional law, as the conditioning only imposes linear relations between Gaussian random variables, so that the resulting conditional random variables are Gaussian and centered. So ![\mathbb{E}[\lvert P''(x)\rvert\mathbf{1}_{P(x)\in B}:P'(x)=0]=\int_{u\in P^{-1}(B),v \in \mathbb{R}}\text{d}u\text{d}v\sqrt{\frac{1+4x^2}{4(2\pi)^2}}\lvert v\rvert e^{-\frac12(u,v)\Sigma_{(P(x),2a)|P'(x)}^{-1}(u,v)^t}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clvert+P%27%27%28x%29%5Crvert%5Cmathbf%7B1%7D_%7BP%28x%29%5Cin+B%7D%3AP%27%28x%29%3D0%5D%3D%5Cint_%7Bu%5Cin+P%5E%7B-1%7D%28B%29%2Cv+%5Cin+%5Cmathbb%7BR%7D%7D%5Ctext%7Bd%7Du%5Ctext%7Bd%7Dv%5Csqrt%7B%5Cfrac%7B1%2B4x%5E2%7D%7B4%282%5Cpi%29%5E2%7D%7D%5Clvert+v%5Crvert+e%5E%7B-%5Cfrac12%28u%2Cv%29%5CSigma_%7B%28P%28x%29%2C2a%29%7CP%27%28x%29%7D%5E%7B-1%7D%28u%2Cv%29%5Et%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Simplifying the problem a bit, we now let 
Realizing that the density of the derivative at 0 is just 
In fact, this says that the critical point of a degree two polynomial is distributed according to Cauchy’s law of location parameter 0 and scale parameter 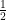


![\mathbb{E}[\lvert P''(x)\rvert:P'(x)=0]=\frac12\sqrt{\frac{1+4x^2}{2\pi}}\int_{v \in \mathbb{R}}\text{d}v\lvert a\rvert e^{-\frac18(1+4x^2)v^2}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Clvert+P%27%27%28x%29%5Crvert%3AP%27%28x%29%3D0%5D%3D%5Cfrac12%5Csqrt%7B%5Cfrac%7B1%2B4x%5E2%7D%7B2%5Cpi%7D%7D%5Cint_%7Bv+%5Cin+%5Cmathbb%7BR%7D%7D%5Ctext%7Bd%7Dv%5Clvert+a%5Crvert+e%5E%7B-%5Cfrac18%281%2B4x%5E2%29v%5E2%7D.&bg=ffffff&fg=000&s=0&c=20201002)

This can be easily confirmed by realizing that the critical point of 

Eigenvalues of the Gaussian Orthogonal Ensemble: We now study another simple example. We want to recover the eigenvalue distribution of the GOE from the Kac-Rice integral. This is a good example as it is a baby version of an important use case for Kac-Rice: the spherical p-spin model. Our example is the (almost) trivial 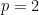
First a reminder. Let 






Keeping the above remark in mind, we now consider 

According to Kac-Rice, up to a factor of 2, the average number of eigenvalues in the interval ![I_u:=(-\infty, u]](https://s0.wp.com/latex.php?latex=I_u%3A%3D%28-%5Cinfty%2C+u%5D&bg=ffffff&fg=000&s=0&c=20201002)
A first remark is that 


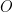


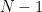
As earlier, we need the joint law of 











This allows us to identifiy the joint law of the joint law of 







Therefore according to Kac-Rice formula, the number of critical point of

Using a classical trick, we can recognize, up to multiplicative constant that 





- I thank them for their patience, their nice remarks and their general curiosity ↩︎
